

Learn how to build a PDF chatbot with Python using Gemini API, LangChain, and ChromaDB. This tutorial walks you through creating a chatbot that can interact with and extract information from PDF documents.
Prerequisites
Before we start, ensure you have the following libraries installed for building a PDF chatbot with Python:
- LangChain: A library for building applications with LLMs through composability.
- ChromaDB: An open-source vector database for embedding-based search.
- PyPDF: A PDF processing library for Python.
You can install these libraries using pip:
pip install google-generativeai langchain-community chromadb pypdfSetting Up the Environment
First, we need to import necessary libraries and set up the API key for Gemini to build our PDF chatbot with Python.
import os
import signal
import sys
import google.generativeai as genai
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddingsGetting the Gemini API Key
To interact with Google’s Gemini API, you need an API key. Here’s how to get it:
- Visit the Google Gemini API page and apply for an API key.
- Google offers a generous free tier with unlimited requests, limited to 60 requests per minute. For more than 60 requests per minute, you might need to opt for a pay-as-you-go plan.
Steps to create an API key:
- On the Google AI for Developers page, click on the “Learn more about the Gemini API” button.
- Next, click on “Get API key in Google AI Studio”.
- Click on the “Get API Key” button positioned on the top left of the screen
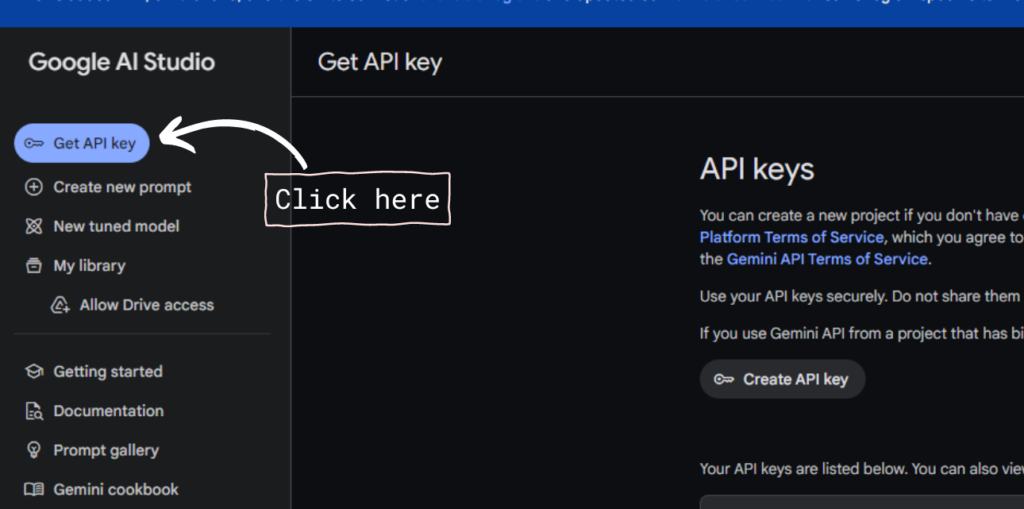
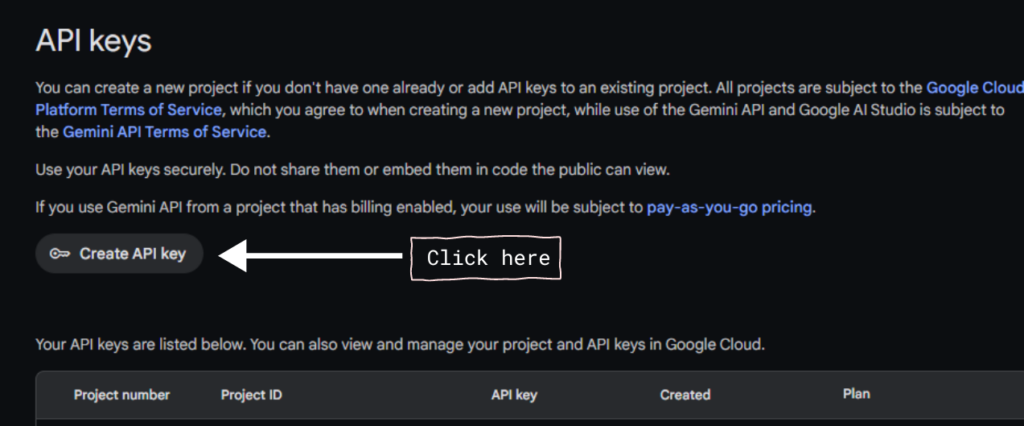
- Click on the “Create API” button and select a project to generate an API.
GEMINI_API_KEY = "your_api_key_here"Handling Signals
To gracefully handle interruptions, we’ll set up a signal handler.
def signal_handler(sig, frame):
print('\nThanks for using Gemini. :)')
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)Generating RAG Prompts
We need to create a function that generates prompts for our Gemini model using the query and context for our PDF chatbot with Python.
def generate_rag_prompt(query, context):
escaped = context.replace("'", "").replace('"', "").replace("\n", " ")
prompt = ("""
You are a helpful and informative bot that answers questions using text from the reference context included below.
Be sure to respond in a complete sentence, being comprehensive, including all relevant background information.
However, you are talking to a non-technical audience, so be sure to break down complicated concepts and
strike a friendly and conversational tone.
If the context is irrelevant to the answer, you may ignore it.
QUESTION: '{query}'
CONTEXT: '{context}'
ANSWER:
""").format(query=query, context=context)
return promptFetching Relevant Context
To provide meaningful answers, we’ll fetch the relevant context from our ChromaDB database.
def get_relevant_context_from_db(query):
context = ""
embedding_function = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_db = Chroma(persist_directory="./chroma_db_nccn", embedding_function=embedding_function)
search_results = vector_db.similarity_search(query, k=6)
for result in search_results:
context += result.page_content + "\n"
return contextGenerating Answers with Gemini
Using the Gemini API, we’ll generate answers based on the provided prompts.
def generate_answer(prompt):
genai.configure(api_key=GEMINI_API_KEY)
model = genai.GenerativeModel(model_name='gemini-pro')
answer = model.generate_content(prompt)
return answer.textWelcome Message
Generate a welcome message to introduce the PDF chatbot.
welcome_text = generate_answer("Can you quickly introduce yourself")
print(welcome_text)
Main Chat Loop
Create a loop to continuously accept queries and provide answers.
while True:
print("-----------------------------------------------------------------------\n")
print("What would you like to ask?")
query = input("Query: ")
context = get_relevant_context_from_db(query)
prompt = generate_rag_prompt(query=query, context=context)
answer = generate_answer(prompt=prompt)
print(answer)Generating Embeddings
Now, let’s generate embeddings for the PDF documents. This will help us in fetching relevant context.
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
loaders = [PyPDFLoader('./report.pdf')]
docs = []
for file in loaders:
docs.extend(file.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(docs)
embedding_function = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2", model_kwargs={'device': 'cpu'})
vectorstore = Chroma.from_documents(docs, embedding_function, persist_directory="./chroma_db_nccn")
print(vectorstore._collection.count())Running the PDF Chatbot Application
To run the PDF chatbot application, execute the script. You will be prompted to input your queries, and the bot will respond with answers based on the text extracted from the PDF.
Get Source Code for free:
Conclusion
Building a PDF chatbot with Python using Gemini API, LangChain, and ChromaDB allows you to extract meaningful insights and interact with the content of any PDF document. By following the steps outlined in this tutorial, you can create a powerful and user-friendly chatbot that can handle various queries and provide comprehensive responses based on the text within the PDF. This project not only demonstrates the capabilities of these technologies but also opens up new possibilities for automating document analysis and enhancing user interaction with text-based data.
Happy Coding….!!!










Leave a Reply